|
Chapter 22Using HTML FORMs with Perl CGI Scripts
CONTENTS
This chapter covers the use of Perl with HTML forms. The topics include collecting information from an HTML FORM and responding to the requested information. I cover two ways of querying information from an HTML script: using the GET and POST methods. I also cover how to acquire and then parse data in the Common Gateway Interface (CGI) script in order to get responses back to the browser. The information presented in this chapter can easily be expanded to cover a whole book. There are many different ways of handling CGI scripts, FORMs, and developing client/server applications, and just as many texts to cover them. A list of references is provided here if you want more information: For more information via printed textbooks, you might want to consult these titles:
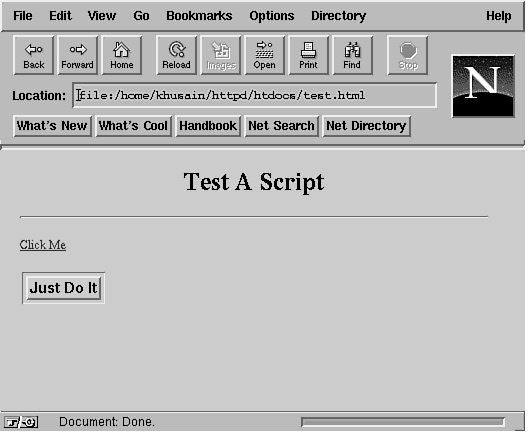
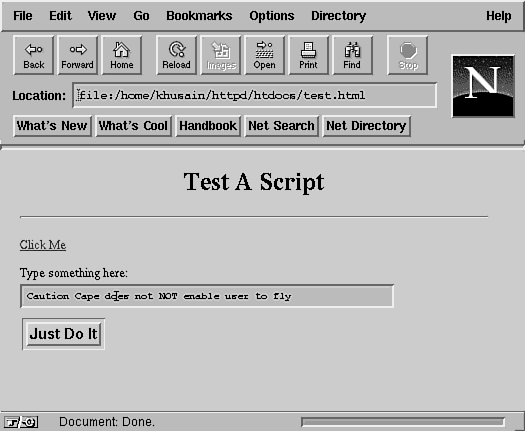
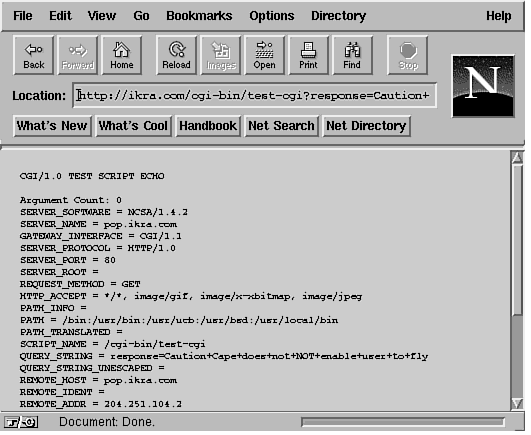
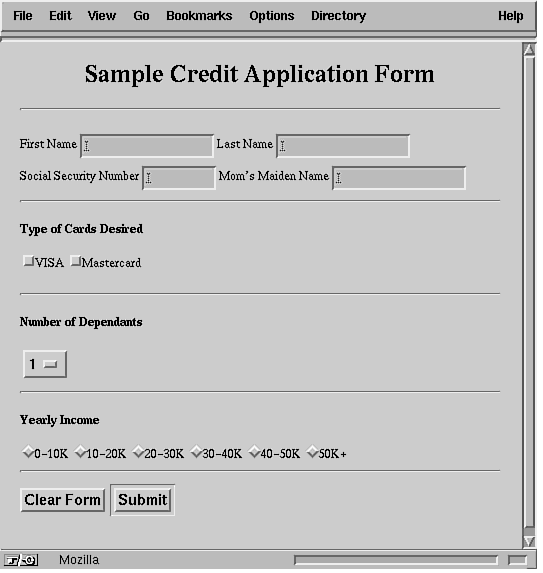
Input and Output with CGIIf you have used a Web browser, then you have come across HTML pages, which allow you to query databases for information. Click a button and-voilà-you get the latest weather in Colorado. Just enter a date and destination and you can click a button to get the travel information you need. What's going on behind the page? Well, the chances are very high that the information handler behind the Web page is a Perl script. Perl's power and ease of handling make it a good choice for setting up support code for Web pages. Before I begin, remember that a CGI script does not have to be written in Perl, but the ease and convenience of handling strings makes Perl a very comfortable choice. Because this book is about Perl, it won't take a wild guess to figure out which language I cover in this chapter. However, you certainly can write CGI scripts in any language you like-tcl/Tk, C, C++, or (gasp) even in Assembler. I'll go over a few points about the terminology in this chapter before I get into the code. An HTML page is picked up and displayed by a browser on the request of a user using that browser. The information handling scripts and executables for that page are handled by the server to which the HTML page's Uniform Resource Locator (URL) points. The server gets a request for action from the browser when the user selects the URL. The request is processed by the server using the CGI, and the results of the CGI executable are sent back to the browser, which in turn displays them to the user. When describing the code that handles the requests, it's easy to use the word user instead of browser. However, as far as the CGI script on the server is concerned, it's sending results back to whoever or whatever called it. It's easy to get the words mixed up, but the intent of both words is to imply the entity that invoked the CGI script in the first place. I introduced you briefly to CGI in Chapter 20, "An Introduction to Web Pages and CGI." In this chapter, I cover how the methods for CGI are implemented in HTML forms. I use the test-cgi.pl shell script (presented earlier) as the basis for setting up shell scripts for returning data in response to a request. Listing 22.1 presents a Perl script to echo CGI environment variables. Listing 22.1. Perl script to echo CGI environment variables. 1 #!/usr/bin/perl I'll examine only the Perl scripting features that apply to CGI. Basically, CGI scripts are executed by the server in response to a request or action by the URL referenced in the HTML document being viewed. For example, a URL refers to this document as follows: <A The output from this script is as follows. I have truncated it to save space. Yet Another CGI/1.0 Test Script The first action is to reply to the server that text is being sent back. This is done with the following statement: print "Content-Type: text/plain\n\n"; Examine this test-cgi.pl Perl script and its associated URL in more detail. Notice how the arguments are being passed into the Perl script. Okay, so I said Its instead of It's, because I did not want to escape the single quote (') between the t and s. HREF="http://ikra.com/cgi-bin/test-cgi?Its+de+a+vu+all+over+again" The script being referred to in this URL is the test-cgi file on the node ikra.com in the subdirectory cgi-bin of the http root directory. The arguments being passed into this script appear after the question mark (?). Each argument is separated by a plus sign (+). The number of arguments, therefore, is six. The string is the now famous saying that is widely attributed to Yogi Berra, "It's déjà vu all over again." Now let's see how the shell script handles this quip. The first line to look at is the one in which $| is set to 1. The $| variable is a special variable in Perl. When the $| variable is set to a non-zero value, Perl forces a flush to the current output channel. When you are working with CGI applications, it's important to keep in mind that a quick response will win you praise. Don't wait for the channel to flush input back to the caller because the buffering on your output might cause the client's browser to wait for input for so long that a timeout is triggered. The next line is absolutely necessary and should be printed back to the browser regardless of how the shell script runs. This line tells the client what type of data you are sending back. In this example, plain text is sent back; it's important to let the browser know about it. This is done by sending back the MIME content identifier: print "Content-Type: text/plain\n\n"; It's nice to know what the returned output is; you can print it out with this line: print "Yet Another CGI/1.0 Test Script\n\n"; Next, all the arguments are printed out back to the browser with the following lines: $count = ($#ARGV + 1); The environment variable QUERY_STRING has the arguments to this shell script in the form of Its+deja+vu+all+over+again. In order to parse this string into individual arguments, you have to split the array where there is a plus sign. This is easily done with the following line (which is not in Listing 22.1): @keywords = split('+', $ENV{QUERY_STRING}); Each element of the @keywords array will be assigned an argument. That is, the array will look like this: @keywords = ("Its", "deja", "vu", "all", "over", "again"); Now you can use these keywords to index into an external database and return an appropriate response. What Are GET and POST?There are two HTTP methods for getting data to a CGI script using an HTML page: GET and POST. The main difference between the two methods of sending data is in the form of a query string to a CGI script. In the GET method, the query string is appended to the URL of the CGI program that will be handling the request. Within the CGI script, the query string will be set to the environment variable QUERY_STRING. In the case of a POST, the browser collects the information from a FORM and presents the data to the CGI script via its standard input. The main advantage of using a POST request over a GET request is that POST requests can be longer than the maximum allowed length (usually 256) for an environment variable. The GET method can be used without having to encode a FORM because all you have to do is append the query string to the calling program's URL and send the resulting string to the CGI program. For example, you could define an anchor tag like this: <A HREF="/cgi-bin/summer.pl?name=Kamran%20Husain&y=3"> CGI Sample</A> This anchor tag will send a GET request to the program summer.pl. The summer.pl program in turn will get the string "name=Kamran%20Husain&y=3" in its environment variable called QUERY_STRING. Note that the question mark (?) in the constructed query string separates the path of CGI script from the parameters to be passed in the QUERY_STRING. Note that the %20 in the name assignment corresponds to the ASCII representation for a space, a hex 20. Spaces and special characters are not permitted in the query string, and so they have to be converted to their ASCII representations. Here's a Perl statement to convert a given string into an encoded query string: $query ~= s/(\W)/sprintf("%%%x",ord($1))/eg; The substitution operator finds all the items that are not words with the \W construct. The parentheses around the match (\W) allow this match to be referenced in the substituted string. The matched word is then replaced by its hex equivalent by evaluating the sprintf statement, as specified by the -e flag. The sprintf command simply replaces each matched string $1 with a percent sign followed by its ordinal value. The substitution is done on the entire string by specifying the -g flag. So, what's going to be the major difference in the way you are going to handle the incoming data in your Perl script? When handling a GET request, you are responding to data in the QUERY_STRING environment variable. When handling the POST request, your Perl script will have to read from STDIN, the default input file handle. In a CGI script, the environment variable REQUEST_METHOD will be set to either GET or POST depending on how the FORM was defined. A FORM can be defined to either method in the <FORM> tag with the METHOD attribute. To use the GET method for a CGI script handleIt.pl, you would use the following statement: <FORM ACTION="/cgi-bin/handleIt.pl" METHOD="GET"> For using the GET method for the same CGI application and FORM, you would use the following statement: <FORM ACTION="/cgi-bin/handleIt.pl" METHOD="POST"> The CGI application you specify in the ACTION attribute of a FORM is called whenever a button of a TYPE attribute "submit" is pressed. To define a "submit" button on a FORM, you can use the following <INPUT> tag: <INPUT TYPE="submit" VALUE="Just do it!"> The line above will create a button on the FORM with a caption set to the string in the VALUE attribute. When this button is pressed, the browser will collect the information from the fields in the FORM and using the method defined in the METHOD attribute of the FORM make a query string and send it to the CGI application defined in the ACTION attribute. Hardwiring a URL with existing question marks and plus signs to set up the input to a CGI script defeats the purpose of having a FORM in the first place. This is where the POST request comes in to tell the browser how to make the input string for you by using the input from a FORM. Handling HTML FORMs with GET MethodsData collected from an HTML form can also be sent for processing with the FORM keyword using the GET method. See the code with the HTML page shown in Listing 22.2. Listing 22.2. Simple FORM input. 1 <html><head> <title>Welcome.</title> The rendering of this listing in Netscape is shown in Figure 22.1. Pressing the Just Do It button returns an argument count of 0. Accept some more input from the user to get more information about the FORM. The modified form is shown in Figure 22.2. Listing 22.3 shows how the text area was inserted. Figure 22.2 : Using a simple form with a text area. The <BR> tag causes a line break and forces the button onto the next line. Without the <BR> tag, the button would be on the same line as the text widget (space permitting). The following tag collects the input for the FORM: Type something here: <INPUT SIZE=60 NAME="response"> The length of the string the user can type in is set to 60 characters wide. The value sent to the shell script from this text widget is assigned to the keyword response. Let's see how the Perl shell script is called when the button is pressed. Listing 22.3. Sample form with text input. 1 <html><head> The output is shown in Figure 22.3. Look closely in the middle of the figure to see the line: Figure 22.3 : The output of the request from the text area. "response=Caution+Cape+does+not+NOT+enable+user+to+fly" Look at the value assigned to QUERY_STRING. The "not+NOT" is deliberately done to catch your eye. As you can see, the string is not easy to read. Look at the title and location of the Netscape window in Figure 22.3. The value of QUERY_STRING is set to a format that is expected by the CGI script at the server. Handling an HTML FORM with POST MethodsHandling the POST method is different than handling the GET method. In the POST method, you use the STDIN line as the source of your input. The length of the string being passed into the POST-handling script is set in the CONTENT_LENGTH identifier. To illustrate the use of CONTENT_LENGTH and POST methods, you'll work with a slightly more complicated input FORM. I'll construct the FORM shown in Figure 22.4. The HTML code for this page is shown in Listing 22.4. The Perl script behind the FORM is shown in Listing 22.5. Figure 22.4 : Sample credit card application form. Listing 22.4. A sample credit card application form. 1 <html><head> <TITLE>Sample Credit Form</TITLE> Here is the output from the credit.pl Perl script: ============================================= SERVER_NAME = pop.ikra.com In this output from the POST request, the REQUEST_METHOD is POST, and the query string is shown as empty! So where did all the user's input go? The input has been pumped into the standard input of the Perl script. You have to design your Perl script to pick the input from either the POST or GET requests automatically. Listing 22.5 illustrates how to process both types of requests. Listing 22.5. The Perl script to handle credit.html. 1 #!/usr/bin/perl Basically, this script handles the input for a GET request with non-empty input and a POST request with any input. At the end of this conditional, $form has the input string in a URL-encoded form. Obviously, this kind of data handling is not acceptable in a real-life scenario. The parsing of the incoming input to figure out if it's POST or GET has to be done so many times and in so many shell scripts that it's really a good idea to simply write a subroutine that handles both types of processing. Once you have such a subroutine defined, all you have to do is simply include it in the rest of the CGI scripts to extract the incoming parameters. In either case, the output of the Perl script is what is sent back to the calling browser. In other words, all the words written to STDOUT (the default if a file handle is not specified in the print statement) are sent the browser. In fact, the output is forced to be flushed as soon as possible with the use of the $|=1 command.
In Listing 22.5, lines 19 through 28 will parse the incoming parameters into an associative array called inputs. Look at what you have parsed into the incoming inputs associative array from a test run. The output of what the values that were entered in the form and sent to the script are set in inputs: %inputs{'income'} is set to 5
If you look at the HTML file that invoked this script, you'll
recognize some of the indices in the %inputs
array. The keys used to index into the %inputs
array were set in the HTML document. They have now been passed
into the Perl script for use. The
%inputs
array now has all the values for you to work with.
Of course, you always have to check the incoming values to see
if they make sense. There are several ways to check the input
for your credit card application example. You could check if the
social security number has the right number of digits, if all
the fields were filled in, and so on. One possible way to check
the input is shown in Listing 22.7. Note how each variable is
tested for a range of values and to see if it's empty. In your
HTML pages and CGI scripts, you must check for missing or inconsistent
responses. Prepare for the worst-case scenario.
The tedious part is checking for all the possible responses that
your user can type in. Checking for non-zero responses, empty
strings, and out-of-range values takes time in execution and in
setting up tests. However, the time will be well spent if the
users of your page are not given Server
Error messages, or, even worse, data on bad input
without even a whimper of an error message. This type of response
may lead to the user actually believing in the erroneous test
results.
The code in line 8 makes the call to the FormArgs
function which extracts all the arguments into an associative
array and returns a value of true if any arguments were extracted
or not. If no values were extracted, the code in line 22 will
bail the program out with an error message.
The loop defined in lines 30 through 37 splits the incoming string
and places all the variable=value
pairs into the %inputs array.
Recall that the input string is in the form var1=value1+subvalue1&var2=value
and so on. Spaces are converted to + signs, each assignment is
separated from the other using an ampersand.
The code in line 30 splits each assignment that is delimited by
ampersands. Then each element is placed in the $pair
variable for use in the for…each
loop statements. In line 31, the element in the $pair
variable is examined to see if it has the form variable=value,
that is there is a word on either side of an equal sign within
the contents of the $pair
variable.
If an assignment is found, the code in line 32 extracts the name
of the variable being assigned to into the $key
variable, and the value in the $value
variable. The contents of the $key
variable will be used to index into the %inputs
array during the rest of the program. The contents of the $value
variable will be that in the $pair
variable. The extra plus (+) signs are replaced with spaces in
line 33. The line is terminated in line 34. Finally in line 35
we actually index into the %inputs
array to assign a value using the $key
value extracted in line 32.
The rest of the lines of code (lines 38 to 71) are pretty straightforward
in the way they check for blank or incorrect input value. Of particular
interest is how the social security number is interpreted in this
script (see line 47). The number can be read in from the user
as XXX-XX-XXXX, where
(X is a decimal digit
from 0 to 9), or as a string of nine decimal digits XXXXXXXXX.
This situation has been taken care of with the two conditions
for the regular expressions.
A social security number is quite meaningless to someone who lives
outside of the United States. When designing pages that are user
specific or where the country of origin matters, it's best to
either provide a warning or an alternative page. How would you
handle a phone number in this scenario? Phone numbers in the United
States are assigned in a different way than they are in a foreign
country. When designing HTML pages, you have to keep these sensitive
and important internationalization factors in mind.
So far I have dealt only with returning messages back in the form
of text data. The beauty of CGI is the ability to send back custom
HTML pages in response to your requests. Instead of sending back
a content-type of plain,
you send back a type of html.
This is done with the following statement:
It's your responsibility to make sure that your script sends back
a valid HTML page regardless of how badly the input is messed
up. The returned page should have the correct <HTML></HTML>
tags and should be syntactically correct. Remember that the browser
will be expecting an HTML page as soon as it sees the context
type of html. Don't forget
the extra empty line. Also, remember to use \n\n
to terminate the string.
Refer to the code in Listing 22.7 to see how the error message
is constructed from an empty string. Basically, the very first
error that occurs is being reported (rather than flooding the
user's screen with a page full of error messages). Naturally,
this is a design decision that you have to make as you design
your HTML pages. Do you inform the user only of the first error,
or do you tell him or her about every conceivable error that has
occurred with the input? Pouring on too many error messages will
only serve to annoy or confuse the user.
This script produces the header for the HTML header and body first
with the code in lines 87 through 91. Line 87 asks Perl to print
everything until the string HTMLHEAD
is found by itself on a line. Line 88 starts a new HTML page,
followed by the start of the body of the page with the <BODY>
tag, and then a blank line with the <P>
tag. Note that I did not use the <TITLE>
and </TITLE> tag pair.
Then, the script examines the $error
string to see if it had any problems listed in it. If no problems
are seen (that is, the $error
string is empty), then the script accepts this input and prints
out an acknowledgment. On the other hand, if there are some problems,
then the script prints out the value of $error
to show what the errors are and print those out instead.
At this point, the script can write out HTML tags and text for
sending back the content of an HTML page to the browser. Regardless
of what the result of action
is, you have to close out the HTML output with the </BODY>
and </HTML> tags. Then
you are done. The response is sent back to the browser, and you
can safely exit.
Perl gives you, as a programmer, enormous flexibility and power
to control how you handle responses and echo back messages. I
used the construct print << "HTML".
Anything from that statement on will be printed to STDOUT
(standard output of the script or until the end of file), until
either that exit statement
or the word HTML is found
by itself on one line.
So far, you've been able to collect the incoming data from the
user and verify that it is correct for the HTML FORM
you are supporting. Now the question is what can you do with the
collected data? Well, basically anything you want, because it's
local to your script now. Two of the most common actions you might
want to take with this data is to archive it to disk or mail the
contents as a message to someone.
The archival process to store the incoming data can be done in
many different ways. You can use the incoming name and other information
to store values in a text string or a database. Using the techniques
covered in Chapter 18, "Databases
for Perl," you can construct your own database. At the very
least, you can archive the responses in a plain text file by appending
them to an existing file.
A simple solution is to use the following lines to write them
all out. It'll be one long text file.
Using a crude method like this might get you by if you have only
a few applicants. The
For a commercial application, you're better off using an existing
database from Oracle, dBASE, or some other commercial database
management system. With a commercial system you're able to use
the DBI to take advantage of particular features of that database.
Perl comes with several modules, including GDBM, NDBM, and SDBM.
For the purpose of illustration, they are functionally the same,
so I'll use GDBM. This will help keep the focus on how to handle
data from within a CGI script, rather than going off into a tutorial
on databases.
In this script, you'll use the GDBM_File.pm
module with the following line:
All Perl modules end with the .pm
extension; the use command
does not require that this be specified. To see if you have the
module in your system, look in the /usr/lib/perl5
directory for all the files ending *.pm.
Next, you have to figure out how to store the users' responses
in this database. An almost-unique key for this application is
the user's $ssn field. Perhaps
you can create the index by concatenation of the $ssn
field with the last name ($lname).
Using this $appIndex variable,
you can index into your sample database, which is called applicants.dbm.
Create this database first and then associate it with the %applicants
associative array. That way, if the applicant has already applied
for credit, you can give him or her an error message or proceed
with updating his or her information. The action to take is really
up to you. The following snippet of code shows how to use DBM
to track applicants:
Basically, you are saving the query string in $form
for future use. Any other script reading the applicants.dbm
file will have to break this string apart to get the individual
words, just like in the credit.pl
script.
Another alternative use of the incoming data is to mail the bulk
of the information to another user. This feature is invaluable
for firms that provide services on the Internet. For example,
you could send a mail message to the sales representative for
a mail-order firm when a FORM
is filled out, or you could send the contents of a bug report
FORM to a help desk representative-basically,
whenever someone fills out your FORM
and you get a mail message saying that they want more information.
Now you can incorporate the mail feature in the Perl script you've
been working with. Look at the section of code you have to add
to get this "mail back" feature. The mail can be sent
just before you exit instead of updating your internal database.
append the following snippet of code to Listing 22.9 to add the
mailing feature to your CGI script:
There are a few points to note concerning the script shown above.
First, a UNIX pipe is opened to the sendmail
program. The | character
in the filename argument tells Perl to open a pipe, not a regular
file. Refer to Chapter 14, "Signals,
Pipes, FIFOs, and Perl," for more information. Now all the
text sent to the MAIL handle
will be sent to the program at the end of the pipe. In this case,
the program at the end of the pipe is the sendmail
program.
The select(MAIL); statement
selects MAIL as the default
file handle for all the output. This is simply a convenience for
me as a script writer. If I do not do this, my print
statements would all have to be of the form print
MAIL. If I inadvertently
forget to specify a MAIL
handle in a print statement,
it will be sent to STDOUT
and not MAIL. You can elect
not to use this method.
The statement for the From
field in the mail message is hardwired to From:
user@using.browser.com. You can add fields in your
HTML FORM to accept a return
mail address and collect it in a field called $returnAddress.
This way, the reply to this mail message is sent directly to the
user. The line of code to set the return address looks like this:
From: $returnAddress.
It would be nice to show the date of the application relative
to the server. (The applicant could be on the other side of the
world for all you know.) The chop
command gets rid of the carriage return at the end of the line
returned from the date command.
The close(MAIL) call terminates
the input to the sendmail
program, which in turn sends the mail out. You can select (STDIN)
again at this point or bail out.
This chapter covered how to write HTML FORM
pages and how to write CGI scripts for handling input. There are
two methods used for querying information from an HTML script:
GET and POST.
The GET method sends the
data collected from the FORM
in the environment variable called QUERY_STRING.
The POST method sends the
data in via the standard input (STDIN)
to the script, and the length of the input is set in the CONTENT_LENGTH
environment variable. Spaces within a value, when passed as an
argument to the script handling the input, are shown as plus signs
(+). Different assignments
to a variable are separated by ampersands (&).
The CGI script can process the input by verifying it for acceptable
parameters and return replies in the form of HTML pages or plain
text. The CGI script then can store the data away in a database,
mail the results to someone else, or both.
|
|||||||||||||||||||
|
With any suggestions or questions please feel free to contact us | ||||||||||||||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}