Оптимизирующие преобразования, которые мы рассматривали выше, оставляли внутреннее представление запроса непроцедурным.
Процедурным представлением или планом выполнения запроса называется такое его представление, в котором детализирован порядок выполнения операций доступа к базе данных физического уровня. Как правило, в реляционных СУБД выделяется подсистема управления данными на физическом уровне. В System R, такая подсистема называется RSS (Relational Storage System) и обеспечивает простой интерфейс, позволяющий последовательно просматривать кортежи отношений, удовлетворяющие заданным условиям на значения полей, с использованием индексов или простым сканированием страниц базы данных. Кроме того, RSS позволяет производить отсортированные временные файлы и заносить, удалять и модифицировать индивидуальные кортежи. Аналогичные подсистемы явно или неявно выделяются во всех подобных СУБД.
Естественно, что до выполнения запроса необходимо выработать его процедурное представление. Поскольку оно, вообще говоря, выбирается неоднозначно, необходимо выбрать среди альтернативных планов запроса один в соответствии с некоторыми критериями. Как правило, критерием выбора плана выполнения запроса является минимизация стоимости выполнения.
Тем самым, при обработке запроса на стадии, следующей за логической оптимизацией, решаются две задачи. Первая задача: исходя из внутреннего представления запроса и информации, характеризующей управляющие структуры базы данных (например, индексы), выбрать набор потенциально возможных планов выполнения данного запроса. Вторая задача: оценить стоимость выполнения запроса в соответствии с каждым альтернативным планом и выбрать план с наименьшей стоимостью.
При традиционном подходе к организации оптимизаторов обе задачи решаются на основе фиксированных встроенных в оптимизатор алгоритмов. Оптимизатор может быть рассчитан на то, что ограничение любого отношения в соответствии с заданным предикатом может быть выполнено путем некоторого последовательного просмотра отношения. Так, запрос
SELECT EMPNAME FROM EMP WHERE DEPT# = 6 AND SALARY > 15.000
может выполняться последовательным сканированием отношения EMP с выбором кортежей с DEPT# = 6 и SALARY > 15.000; сканированием отношения через индекс I1, определенный на поле DEPT#, с условием доступа к индексу DEPT# = 6 и условием выборки кортежа SALARY > 15.000; наконец, сканированием отношения через индекс I2, определенный на поле SALARY, с условием доступа к индексу SALARY > 15.000 и условием выборки кортежа DEPT# = 6.
Аналогично, фиксированы и стратегии выполнения более сложных операций - реляционных соединений отношений, вычисления агрегатных функций на группах кортежей отношения и т.д. Например, в System R для (экви)соединения двух отношений используются две основные стратегии: метод вложенных циклов и метод сортировок со слияниями.
Компонент оптимизатора, генерирующий выполняемые планы запросов, имеет достаточно сложную организацию; генерация плана выполнения сложного запроса - это многоэтапный процесс, в ходе которого учитываются свойства создаваемых при выполнении запроса по данному плану временных объектов базы данных. Например, пусть запрос задан над тремя отношениями и в нем имеются два предиката соединения:
SELECT R1.C1, R2.C2, R3.C3 FROM R1, R2, R3 WHERE R1.C4 = R2.C5 AND R2.C5 = R3.C6.
Тогда, если в плане запроса выбирается порядок выполнения соединений сначала R1 с R2, а затем полученного временного отношения - с R3, и при этом для выполнения первого соединения выбирается метод сортировок со слиянием, то временное отношение будет заведомо отсортировано по C5, и одна сортировка не потребуется, если и второе соединение будет выполняться тем же методом.
Компонент оптимизатора, ведающий порождением множества альтернативных планов выполнения запроса, базируется на стратегиях декомпозиции запроса на элементарные составляющие и стратегиях выполнения элементарных составляющих. Первая группа стратегий определяет пространство поиска оптимального плана выполнения запроса, вторая направлена на то, чтобы в этом пространстве действительно находились эффективные планы выполнения запроса. Ключом к обеспечению эффективного выполнения сложного запроса является наличие эффективных стратегий выполнения элементарных составляющих. Это очень важный вопрос, но здесь мы его не касаемся: оптимизатор запросов пользуется заданными стратегиями. Рассмотрим более актуальную для оптимизатора проблему - обоснованный выбор плана выполнения запроса из множества альтернативных планов.
После генерации множества планов выполнения запроса на основе разумных стратегий декомпозиции и эффективных стратегий выполнения элементарных операций нужно выбрать один план, в соответствии с которым будет происходить реальное выполнение запроса. При неверном выборе запрос будет выполнен неэффективно. Прежде всего необходимо определить, что понимается под эффективностью выполнения запроса. Это понятие неоднозначно и зависит от специфики операционной среды СУБД. В одних условиях можно считать, что эффективность выполнения запроса определяется временем его выполнения, т.е. реактивностью системы по отношению к обрабатываемым ею запросам. В других условиях определяющей является общая пропускная способность системы по отношению к смеси параллельно выполняемых запросов. Тогда мерой эффективности запроса можно считать количество системных ресурсов, требуемых для его выполнения и т.д.
Следуя принятой терминологии, мы будем говорить о стоимости плана выполнения запроса, определяемой ресурсами процессора и устройств внешней памяти, которые расходуются при выполнении запроса.
В традиционных реляционных СУБД выделяется подсистема управления доступом к данным на внешней памяти (RSS в System R). Данные на внешней памяти традиционно хранятся в блокированном виде; база данных занимает некоторый набор блоков одного или нескольких дисковых томов. Предполагается, что средства доступа к блокам внешней памяти порождают несравненно меньшие накладные расходы.
Как правило, подсистема управления доступом к данным на внешней памяти осуществляет буферизацию блоков базы данных в оперативной памяти. Каждый блок базы данных, прочитанный в оперативную память для выполнения запроса, сохраняется в одном из буферов буферного пула СУБД, пока не будет вытеснен из него другим блоком базы данных. Эта особенность СУБД существенна для повышения общей эффективности системы, но не учитывается (за исключением частного, но важного случая) при оценках стоимостей планов выполнения запроса. В любом случае компонент стоимости выполнения запроса, связанный с ресурсами устройств внешней памяти, монотонно зависит от числа блоков внешней памяти, доступ к которым потребуется при выполнении запроса.
С другой стороны, число блоков внешней памяти, доступ к которым требуется при выполнении запроса, монотонно зависит от числа кортежей, затрагиваемых запросом.
Из этого следует важность показателя предиката ограничения, характеризующего долю кортежей отношения, которые удовлетворяют данному предикату, и называемого степенью селективности предиката. Степени селективности простых предикатов вида R.C op const, где R.C задает имя поля отношения базы данных, op - операция сравнения (=, !=, >, <, >=, <=), а const - константа, являются основой для оценок стоимости планов запроса. Точность оценок степеней селективности определяет точность общих оценок и правильность выбора оптимального плана запроса.
Степень селективности предиката R.C op const зависит от вида операции сравнения, значения константы и распределения значений поля C отношения R в базе данных. Первые два параметра селективности могут быть известны при проведении оценок, но истинные распределения значений полей отношений, как правило, неизвестны. Существует ряд подходов к приближенным определениям распределений на основе статистической информации. Далее мы рассмотрим наиболее интересные из них.
Если известна степень селективности предиката ограничения отношения, то тем самым известна и мощность результирующего отношения (обычно мощности хранимых отношений известны при обработке запроса). Но в оценочных формулах учитывается необходимое для выполнения запроса число обменов с внешней памятью. Конечно, число кортежей является верхней оценкой требуемого числа обменов, но эта оценка может быть очень завышенной. Все зависит от распределения кортежей по блокам внешней памяти. В ряде случаев можно получить более точную оценку числа блоков.
Наконец, для сложных запросов, включающих, например, соединения более двух отношений, требуется оценивать размеры возникающих в процессе выполнения запроса промежуточных отношений. Чтобы оценить мощность результата соединения двух отношений, вообще говоря, необходимо знать степень селективности предиката соединения по отношению к прямому произведению отношений-операндов. В общем случае степень селективности такого предиката невозможно определить на основе простой статистической информации. Обычно применяются достаточно грубые эвристические оценки, хотя предлагаются и подходы, обеспечивающие большую точность.
Подход System R базируется на двух основных предположениях о распределениях значений полей отношений: предполагается, что значения полей всех отношений базы данных распределены равномерно и что значения любых двух полей распределены независимо. Первое предположение позволяет оценивать селективность простых предикатов на основе скудной статистической информации о базе данных. На втором предположении основываются оценки числа блоков, в которых располагается известное количество кортежей. Эти два предположения являются предметом критики System R. Они сделаны исключительно в целях упрощения оптимизатора и не могут быть теоретически обоснованы. Можно привести примеры баз данных, для которых эти предположения не оправданы. В этих случаях оценки оптимизатора System R будут неверны.
В каталогах базы данных для каждого отношения R сохраняется число кортежей в данном отношении (T) и число блоков внешней памяти, в которых располагаются кортежи отношения (N); для каждого поля C отношения хранится число различных значений этого поля (CD), минимальное хранимое значение этого поля (CMin) и максимальное значение (CMax).
При наличии такой информации с учетом первого базового предположения степени селективности простых предикатов вычисляется просто (и точно, если распределение на самом деле равномерно). Пусть SEL (P) - степень селективности предиката P.
Тогда
SEL (R.C = const) = CD / (CMax - CMin)
(при равномерном распределении степень селективности такого предиката не зависит от значения константы).
SEL (R.C > const) = (CMax - const) / (CMax - CMin)
и т.д.
При оценках числа блоков, в которых могут располагаться кортежи, удовлетворяющие предикату R.C op const, различаются случаи кластеризованности или некластеризованности отношения по полю C. Эти оценки имеют смысл только при рассмотрении варианта сканирования отношения с использованием индекса на поле C. При просмотре отношения без использования индекса понадобится всегда обратиться ровно к N блокам внешней памяти.
Предположения о равномерности распределений значений атрибутов отношений позволяют достаточно просто оценивать и мощности отношений, являющихся результатами двухместных реляционных и теоретико-множественных операций над отношениями.
Оценки селективности предикатов используются и для оценки затрат ресурсов процессора. Предполагается, что основная часть процессорной обработки производится в RSS. Поэтому процессорные затраты измеряются числом обращений к RSS, которое соответствует числу кортежей, получаемых при сканировании хранимого или временного отношения, т.е. селективностью логического выражения, состоящего из простых предикатов (условие выборки уровня RSS). Предположения о равномерности и независимости значений разных полей отношения позволяют легко оценить селективность логического выражения, составленного из простых предикатов, при известных их степенях селективности.
На самом деле в System R не оценивается селективность предикатов в чистом виде. Оценки оптимизатора основываются на фиксированном наборе элементарных оценочных формул, опирающихся на статистическую информацию о базе данных. Каждая формула соответствует некоторому элементарному действию системы; выполнение любого запроса состоит в комбинации некоторых элементарных действий. Примерами элементарных действий могут быть выполнение ограничения отношения путем его сканирования через кластеризованный индекс, сортировка отношения, соединение двух ранее отсортированных отношений и т.д. Общая оценка плана выполнения запроса производится в итерационном процессе, начиная с оценок элементарных операций над хранимыми отношениями.
Перейдем к рассмотрению подходов к более точным оценкам стоимости выполнения планов запроса. Эти подходы можно разбить на два класса. При использовании подходов первого класса оптимизатор сохраняет жесткую структуру, аналогичную структуре оптимизатора System R, но проведение оценок основывается на более точной статистической информации, характеризующей распределения значений. Предложения второго класса более революционны и исходят из того, что для произведения планов выполнения запросов и их оценок оптимизатор должен снабжаться некоторой информацией, характерной для конкретной области приложений.
При отказе от предположения о равномерности распределения значений поля отношения необходимо уметь установить реальное распределение значений. Существует два базовых подхода к оценкам распределения значений поля отношения: параметрический и основанный на методе сигнатур. Подход System R является тривиальным частным случаем метода параметрической оценки распределения - любое распределение оценивается как равномерное. В более развитом подходе было предложено использовать для оценки реального распределения значений поля отношения серию распределений Пирсона, в которую входят распределения от равномерного до нормального. Распределение выбирается из серии путем вычисления нескольких параметров на основе выборок реально встречающихся значений. Примеры практического применения этого подхода нам неизвестны.
Метод оценки распределения на основе сигнатур в целом можно описать следующим образом. Область значений поля разбивается на несколько интервалов. Для каждого интервала некоторым образом устанавливается число значений поля, попадающих в этот интервал. Внутри интервала значения считаются распределенными по некоторому фиксированному закону (как правило, принимается равномерное приближение). Рассмотрим два альтернативных подхода, связанных с сигнатурным описанием распределений.
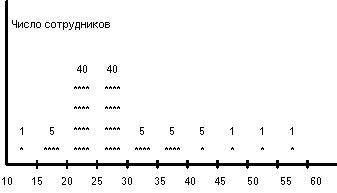
При традиционном подходе область значений поля разбивается на N интервалов равного размера, и для каждого интервала подсчитывается число значений полей из кортежей данного отношения, попадающих в интервал. Предположим, что EMP расширено еще одним полем AGE - возраст сотрудника. Пусть всего в организации работает 60 сотрудников в возрасте от 10 до 60 лет. Тогда гистограмма, изображающая распределение значений поля AGE может иметь вид, показанный ниже на рисунке. Гистограмма построена исходя из разбиения диапазона значений поля AGE на 10 интервалов.
Рассмотрим, как можно оценивать селективность простых предикатов, задаваемых на поле AGE, с использованием такой гистограммы. Пусть в интервал значений AGE Si попадает Ki значений. Тогда SEL (EMP.AGE = const), если значение константы попадает в интервал значений Si, можно оценить следующим образом: 0 <= SEL (EMP.AGE) <= Ki/T (T - общее число кортежей в отношении EMP). Отсюда средняя оценка степени селективности предиката - Ki / (2 ( T). Например, SEL (AGE = 29) оценивается в 40/200 = 0.2, а SEL (AGE = 16) оценивается в 5/200 = 0.025. Это, конечно, существенно более точные оценки, чем те, которые можно получить, исходя из предположений о равномерности распределений. Но не так хорошо обстоят дела с оценками селективности простых предикатов с неравенствами.
Например, пусть требуется оценить степень селективности предиката EMP.AGE < const. Если значение константы попадает в интервал Si, и SUMi - суммарное количество значений AGE, попадающих в интервалы S1, S2, ..., Si, то SUMi-1 / T <= SEL (AGE < const) <= SUMi / T. Тогда средняя оценка степени селективности (SUMi-1 + SUMi) / (2 ( T), и ошибка оценки может достигать половины веса подобласти, в которую попадает значение константы предиката. Самое неприятное, что ошибка оценки зависит от значения константы и тем больше, чем больше значений поля содержится в соответствующем интервале гистограммы. Например, SEL (AGE < 29) оценивается как 46/100 <= SEL (AGE < 29) <= 86/100, откуда оценка степени селективности (46 + 86) / 200 = 0.66; при этом ошибка оценки может достигать 0.2. В то же время SEL (AGE < 49) оценивается существенно более точно.
Для устранения этого дефекта был предложен другой подход к описанию распределений значений поля отношения. Идея подхода состоит в том, что множество значений поля разбивается на интервалы вообще говоря разного размера, чтобы в каждый интервал (кроме, вообще говоря, последнего) попадало одинаковое число значений поля. Количество интервалов выбирается исходя из ограничений по памяти, и чем оно больше, тем точнее получаемые оценки. При разбиении области значений на десять интервалов получаемая псевдогистограммная картина распределений значений поля AGE показана на рисунке ниже.
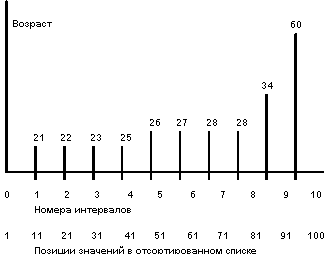
Область значений поля AGE отношения EMP разбита на 10 интервалов таким образом, что в каждый интервал попадает ровно по 10 значений поля AGE. Интервалы имеют разные размеры. Граничные значения интервалов показаны над вертикальными линиями. В псевдогистограмме допустимы интервалы, правая и левая граница которых совпадают, например, интервал (28,28). Он образовался по причине наличия в отношении EMP большого (большего десяти) числа кортежей со значением AGE = 28.
При использовании "псевдогистограммы" ошибки в оценках степеней селективности предикатов с операцией, отличной от равенства, уменьшаются. Размер ошибки не зависит от значения константы и уменьшается при увеличении числа интервалов.
Недостатком метода псевдогистограмм по сравнению с методом гистограмм является необходимость сортировки отношения по значениям поля для построения псевдогистограммы распределений значений этого поля. Известен подход, позволяющий получить достоверную псевдогистограмму без необходимости сортировки всего отношения.
Подход основывается на статистике Колмогорова, из которой применительно к случаю реляционных баз данных следует, что если из отношения выбирается образец из 1064 кортежей, и b - доля кортежей в образце со значениями поля C < V, то с достоверностью 99% доля кортежей во всем отношении со значениями поля C < V находится в интервале [b-0.05, b+0.05]. При уменьшении мощности образца достоверность, естественно, уменьшается.