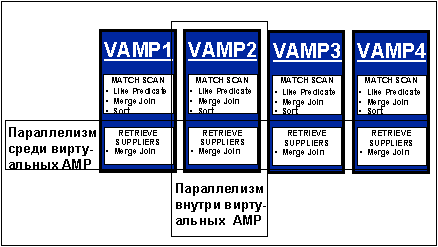
Многомерный параллелизм
Равномерное распределение данных на диске обеспечивается при помощи использования хэш-алгоритма. Кроме того, каждому виртуальному процессору AMP передаются не только одинаковые по объему данные, но и одинаковые вычислительные мощности (ЦП и ПАМЯТЬ). Виртуальные процессоры работают параллельно как на узле SMP, так и на многих узлах SMP. Тем самым они образуют основную или горизонтальную составляющую параллелизма и взаимодействуют друг с другом, используя коммуникационный слой передачи сообщений (Message Passing Layer).
Кроме того, помимо только что описанного горизонтального параллелизма Inter-Vproc, каждый виртуальный процессор AMP реализует вертикальный параллелизм (Intra-Vproc). В каждом виртуальном процессоре AMP имеется большое число рабочих подпроцессов, находящихся в очереди и ожидающих запуска. По мере увеличение загрузки виртуального процессора AMP, динамически увеличивается и число активных подпроцессов в рамках этого АМР. Когда оптимизатор сгенерировал несколько шагов по выполнению запроса, то их можно параллельно выполнить на нескольких виртуальных процессорах AMP, при этом в рамках каждого АМР-а параллельно запускаются на выполнение несколько подпроцессов. Эти подпроцессы образуют вторичную или вертикальную составляющую параллелизма и взаимодействуют друг с другом через глобальную разделяемую память.
Архитектура СУБД Teradata способна эффективно использовать эту двухмерную модель параллелизма как при работе на одном виртуальном процессоре, так и при работе на нескольких виртуальных процессорах. На представленном ниже рисунке дана иллюстрация многомерного параллелизма.
Многомерный параллелизм
Распределение данных
Равномерное распределение данных - это ключевое понятие при реализации распределенной, параллельной загрузки системы. Для реализации равномерного распределения данных СУБД Teradata использует одну схему распределения, основанную на использовании хэш-алгоритма. Данные обрабатываются с помощью достаточно сложного алгоритма хэширования и автоматически распределяются между всеми виртуальными процессорами AMP, в соответствии с результатами этого хэширования. Данный алгоритм зарекомендовал себя как чрезвычайно эффективный для равномерного распределения данных. Он используется с 1983 года, и в течении всего последующего периода корпорация Teradata постоянно совершенствовала его для устранения неравномерного распределения данных, даже когда размер данных БД превышал 100 Тбайт. На показанном далее рисунке иллюстрируется схема фрагментации данных.
Хэш-фрагментация
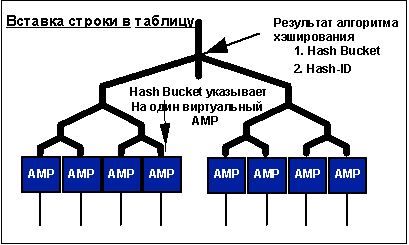
При вставке строки в таблицу выполняется обработка значений в колонках, по которым объявлен первичный индекс. Это значение прогоняется через алгоритм хэширования. При этом вычисляются значения Hash Backet и Hash ID (хэш-идентификатор). СУБД Teradata всего имеет 65 535 значений Hash Bucket, которые распределяются случайным образом между всем виртуальными процессорами АМР. Если колонки, образующие первичный индекс вставляемой строки, были выбраны нужным образом (для обеспечения равномерности данные в этих колонках должны быть уникальны или почти уникальны), то погрешность равномерности распределения данных составляет порядка 0.5%. Именно значение Hash Bucket, вычисленное алгоритмом хэширования, и определяет, какому виртуальному процессору AMP принадлежит нужная строка. Дело в том, что строка будет храниться на дисках, принадлежащих виртуальному данному виртуальному процессору AMP.
Еще раз подчеркнем: в СУБД Teradata для размещения данных используется только схема хэширования. Данная методология размещения данных имеет важное значение для обеспечения равномерной загрузки системы, что необходимо для поддержки высокоскоростной параллельной обработки данных. Поэтому СУБД Teradata не предоставляет никаких других способов размещения данных, чтобы поддерживать равномерность загрузки внутри всей системы в целом.
Кроме того, в СУБД Teradata не выделяется заранее файловое пространство, а администратор БД заранее не рассчитывает, сколько места займет каждая таблица и на каком диске она должна находится. Таким образом, размещение данных полностью автоматизировано. На следующем рисунке объекты представляют все данные, которые размещаются на одном виртуальном процессоре AMP.
Распределение данных СУБД Teradata
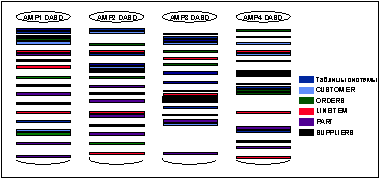
При использовании этого метода размещения данных, строки каждой таблицы распределяются равномерно. Данные при этом равномерно распределяются по всем виртуальным процессорам AMP, и поэтому эффективность работы СУБД не зависит от размещения строк на физических устройствах. Пространство для размещения строк таблицы выделяется по мере необходимости - а не заранее, как традиционных БД. При использовании равномерного распределения данных достигается также полный параллелизм при выполнении операций ввода/вывода.
Все существующие СУБД обладают существенным недостатком: в этих БД весьма болезненной и часто используемой операцией является операция переупорядочивания данных и индексов. Приятным исключением является СУБД Teradata. Структуры файловой системы СУБД Teradata спроектированы таким образом, чтобы гарантировать, что они будут использоваться оптимально даже при выполнении большого числа операций вставки, обновления и удаления записей. В СУБД Teradatа никогда не появляются хэш-цепочки (hash chains). В этой СУБД не появляются несбалансированные B-деревья. В ней также отсутствует какая-либо фрагментация индексных структур верхнего уровня.
Продолжим перечисление достоинств СУБД Teradata: в этой СУБД не производится выделение фиксированного дискового пространства для таблиц (TABLESPACES) или для каких-либо иных целей. Все таблицы и промежуточные пулы могут расти или уменьшаться как угодно, без какого-либо вмешательства со стороны администратора БД или системного администратора. Все свободное дисковое пространство всегда доступно для всех пользователей. Управление используемым пространством осуществляется с помощью ограничений, заданных для каждого пользователя или БД.
Назад | Содержание | Вперед