Ключевые моменты развития технологии Sybase
Для компании Sybase 1998 год является особенным. Прежде всего, сейчас корпорация обладает наиболее широким кругом программных продуктов и технологий за всю свою историю. Кроме того, для всех программных продуктов корпорации в течении последнего года были выпущены новые версии (а для некоторых - даже несколько версий), включая все СУБД, технологии репликации и доступа к данным, технологии для создания прикладных серверов, а также инструменты разработки и проектирования. Еще важнее то, что изменения происходят в рамках объявленной в весной 1997 года, единой стратегии развития технологии - Адаптивной Компонентной Архитектуры Sybase.
Интересно отметить, что новая стратегия является логическим продолжением базового набора технологических решений, впервые появившихся в конце восьмидесятых годов. С самого начала своей деятельности на рынке информационных технологий (с 1988 года), корпорация Sybase сразу позиционировала себя как производителя набора технологий для создания распределенных гетерогенных информационных систем. В базовый набор технологий Sybase, которые принесли компании успех и известность на рынке в течении последующих десяти лет, входят как рад технологий реляционных СУБД, так и различные технологии интеграции для обмена данными и транзакциями между разнородными СУБД и другими (в общем случае, произвольными) источниками данных.
Среди технологий интеграции, необходимо упомянуть набор открытых интерфейсов Sybase Open Client/Open Server, которые были впервые выпущены в 1988 году. В сущности, именно эти интерфейсы легли в основу всех существующих программных продуктов Sybase.
Оригинальность подхода в наборе интерфейсов Open Client/Open Server состояла в том, что многие положения архитектуры "клиент-сервер" были впервые воплощены в области архитектуры СУБД. Библиотека Open Client (раннее название - DB-Library) реализует функции произвольной программы-"клиента": сформировать запрос, послать его на обработку, обработать результаты и воспроизвести их на клиентской машине. Запрос на обработку может быть произведен двумя способами: либо передачей текстового буфера, либо с помощью функций вызова удаленной хранимой процедуры. Библиотека Open Server, в свою очередь, реализует все необходимые функции произвольной программы-"сервера": перехват событий "подключение клиента", "отключение клиента", "приход текстового буфера", "вызов удаленной хранимой процедуры" и других. Кроме того, любая серверная программа, использующая Open Server, сразу является "многопоточной" (multithreading), т.е. при ее запуске создается один процесс операционной системы, а все клиентские подключения происходят в рамках этого же "серверного" процесса, где каждое клиентское подключение представляют собой один поток (thread). Управление же потоками, их переключение, синхронизация и прочее, уже встроено в Open Server на системном уровне. Многопоточность является важным свойством для серверной программы, потому что создание одного потока в рамках одно процесса операционной системы требует на порядок меньше ресурсов, чем создание еще одного процесса. Программы на основе Open Client и Open Server общаются между собой с помощью высокоуровнего протокола обмена данными под названием TDS (Tabular Data Stream - Табличный Поток Данных), который, как следует из названия, оптимизирован на передачу табличных данных. Уровень передачи данных является полностью независимым от сетевых протоколов передачи данных, поэтому клиентская программа может общаться с любым сервером используя распространенные транспортные протоколы (SPX/IPX, TCP/IP, DECNet, AppleTalk и другие). Также, интересной особенностью этих интерфейсов является возможность реализации асинхронного взаимодействия клиентской и серверных программ, когда прикладное серверное приложение имеет возможность вызывать процедуры на клиентской программе ("активный прикладной сервер"). В результате, клиентское приложение получило возможность не ждать окончания обработки на сервере для продолжения своей работы.
На основе Open Server и была создана СУБД Sybase SQL Server, которая обладала целым рядом важных особенностей. SQL Server воплощал в себе подход "интеллектуальной" СУБД, которая на просто хранит данные, а также позволяет хранить прикладные правила хранения данных и прикладные алгоритмы обработки этих данных. Задачей, на которую нацеливался SQL Server, являлась быстрая обработка операций по вводу и модификации данных большим количеством пользователей. Благодаря тому, что в основе лежит Open Server, SQL Server сразу стал многопоточным. Следствием этого явилось небольшое количество памяти, необходимой для поддержки одного клиентского соединения - около 60-70К. Централизованное хранение, изменение и дополнение прикладной логики реализуется с помощью хранимых процедур, триггеров, правил (rules), значений по умолчанию (defaults). Таким образом, если не будут изменены аргументы хранимых процедур или их названия, клиентские программы никогда не узнают, что на сервере произошли какие-то изменения. Кроме того, сервер СУБД оказался не привязанным к типу клиентского приложения, благодаря тому, что, например, все правила, связанные с проверкой новых значений перед их вставкой в таблицу хранятся на самом сервере, а не встроены в код клиентской программы. Это серьезно повышает переносимость клиентских программ и повышает общую безопасность системы в целом.
Кроме того, на основе Open Client/Open Server созданы различные прикладные сервера, выполняющие разнообразные функции в распределенной информационно системе: специализированный сервер для резервного сохранения и восстановления данных Backup Server, специализированный сервер для тиражирования данных Replication Server, специализированный сервер для объединения разнородных баз данных в логически единую базу - Sybase OmniCONNECT и ряд других. Все эти сервера используют единый интерфейс доступа (Open Client) и могут взаимодействовать друг с другом (с помощью вызовов удаленных хранимых процедур) независимо от аппаратной платформы и сетевого протокола. Разумеется, что разработчики информационных систем имеют возможность создавать свои собственные прикладные сервера для решения конкретных задач (например, сложных вычислений, реализации специфических алгоритмов шифрования и аутентификации, организации доступа к каким-либо датчикам или установкам и т.д.), доступ к которым осуществляется с помощью единого протокола обмена данными.
С выпуском в 1993 году первой версии сервера репликации транзакций Sybase Replication Server, компания серьезно укрепила свою репутацию поставщика технологий для создания распределенных систем. Это произошло благодаря тому, что это была первая реализаций технологии репликации транзакций (с сохранением их целостности при их передаче через ненадежные или низкоскоростные линии связи) для СУБД, которая основывалась на чтении изменений из журнала транзакций и последующей их записью в очередь, при проблемах с линией связи. Кроме того, особенностью Replication Server, которая часто привлекает внимание разработчиков, является возможность использования в качестве источника данных для репликации не только любые СУБД Sybase, но и СУБД других известных производителей, включая Oracle или DB2/400 for AS/400. Это реализуется с помощью дополнительных репликационных агентов для соответствующей СУБД.
Взгляд Sybase на разработку и развитие современных информационных систем
Изменения, повсеместно происходящие в информационных технологиях, приводят к появлению новых возможностей и новых задач. Работа компаний и организаций в условиях увеличивающейся конкуренцией становиться все более и более зависящей от обработки больших объемов разнородной информации. Адаптивная Компонентная Архитектура связывает в единое целое все программные продукты Sybase и обеспечивает возможность создания современных законченных решений для информационных систем любой сложности. Эта комплексная архитектура, составной частью которой является СУБД Adaptive Server, предназначена для:
Заложенные в Адаптивную Компонентную Архитектуру принципы адаптации приложений к существующим условиям работы делают ее наиболее гибким и надежным решением для построения систем управления базами данных на сегодняшнем рынке программного обеспечения. Основой такой гибкости является идеология повторного использования программных компонент. Создавая программные компоненты в виде законченных программных "блоков", вы можете быстро разрабатывать отлаженные приложения, а компоненты могут быть использованы на любом из трех уровней Адаптивной Компонентной Архитектуры - клиентском, промежуточном (прикладном) или уровне СУБД.
Компоненты, используемые в Адаптивной Компонентной Архитектуре, разделяются на два вида - компоненты, (1) содержащие логику приложений и (2) данные. Эти два типа компонент могут быть представлены в следующим виде:
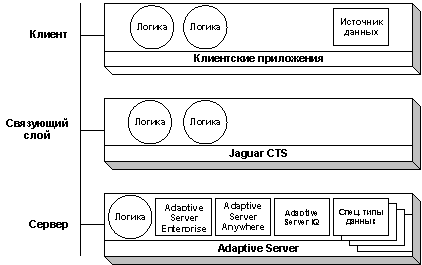
Три уровня Адаптивной Компонентной Архитектуры Sybase показаны на Рис.1. Компоненты, содержащие логику приложения и данные, могут быть размещены на любом уровне. На серверном уровне расположена СУБД Adaptive Server, которая включает в себя компоненты обработки данных Sybase - Adaptive Server Enterprise, Adaptive Server Anywhere и Adaptive Server IQ, а также компоненты для обработки сложных типов данных (текст, графические образы и другая неструктурированная информация).
Рис.1. Адаптивная Компонентная Архитектура
Архитектура СУБД Adaptive Server
Архитектура СУБД Adaptive Server позволяет совместно использовать один или несколько компонентов обработки данных (в зависимости от специфики решаемой задачи). При этом, Adaptive Server будет поддерживать все операции с этими компонентами обработки данных, обеспечивая при этом единый интерфейс доступа (Open Client), единые языки (SQL и Java), единый инструмент администрирования (Sybase Central), а также, при необходимости, единые технологии по репликации транзакций (Replication Server, SQL Remote), обмену сообщениями (dbQueue), интеграции разнородных данных (OmniConnect), интеграцию с web-технологиями (Jaguar CTS и PowerDynamo).
На Рис.2 изображены три составные части Adaptive Server:
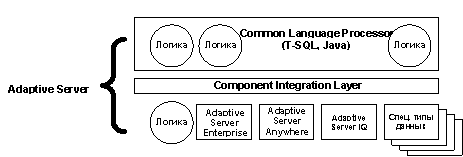
Рис.2. Архитектура Adaptive Server
Компоненты обработки данных включают в себя:
Версия Adaptive Server Enterprise, вышедшая в конце марта этого года поддерживает гибкую технологию управления блокировками, которая может происходить на уровне базы данных, таблицы, отдельной страницы таблицы или же на уровне записи.
Дополнительно к этому, в версии Adaptive Server Anywhere 6.0, которая появляется весной этого года, будет добавлена поддержка языка Java и обеспечена поддержка многопроцессорных (SMP) систем. Кроме того, появиться поддержка новой операционной системы Windows CE (для этой платформы, требования к оперативной памяти снижены до 500K). Во второй половине года планируется выход специальной версии Adaptive Server Anywhere, которая будет полностью реализована на Java и предназначена для использования в качестве встраиваемой СУБД в различных мобильных устройствах (например, в мобильных телефонах).
Новые возможности для разработки прикладных систем
В рамках Адаптивной Компонентной Архитектуры компания Sybase разрабатывает технологию использования языка Java непосредственно в СУБД Adaptive Server. Это позволит существенно повысить открытость и продвинутость серверных программ, а также упростить внедрение и эксплуатацию прикладных систем, основывающихся на серверные программы. В тоже время, это позволит создать открытую объектно-ориентированную СУБД.
Главной целью Java-инициативы компании Sybase является решение проблем, с которыми сталкиваются организации, применяющие информационные технологии
Сегодня, прикладные программы состоят из кода, находящегося вне сервера СУБД и запрограммированного на языках третьего (C/C++, Java и другие) или четвертого поколений (PowerBuilder, Visual Basic и другие), а также из кода, находящегося в СУБД, в виде хранимых процедур, написанных на языке SQL.
Java-инициатива компании Sybase, опираясь на принцип Java-программ ("написал один раз - работает везде "), переносит его действие на новую платформу - СУБД. Это позволит убрать различия между программированием клиентской и серверной частей прикладной системы.
Особенности
Java-инициатива компании Sybase открывает новые возможности для разработчиков прикладных систем.
Открытость и поддержка стандартов
Успех технологии Sybase является следствием приверженности компании к открытым стандартам.
Использование языка Java в реляционной архитектуре позволит убрать барьеры при создании прикладных программ, однако новым препятствием может стать проблема стандартизации новой технологии.
Компания Sybase, совместно с корпорацией JavaSoft, американским комитетом по стандартизации ANSI и консорциумом JSQL, работает над созданием стандартов по использованию языка Java в СУБД.
Почему используется Java?
Одной из важнейших целей компании Sybase является упрощение процесса разработки прикладных информационных систем предприятий, сложность которых постоянно возрастает. Мы уверены, что использование языка Java поможет достичь этой цели.
Java представляет собой язык программирования для нового поколения прикладных информационных систем, который примечателен прежде всего благодаря повышению эффективности процесса разработки приложений. Компания Sybase убеждена, что язык Java позволит повысить эффективность разработки серверных приложений, а также расширить возможности серверов баз данных.
Это убеждение основывается на следующих причинах:
Компания Sybase видит два направления использования языка Java в СУБД:
Следующие разделы посвящены обсуждению реализации этих двух направлений.
Использование Java для программирования СУБД
Современные сервера баз данных применяют SQL для достижения двух задач: доступа к данным и программирования прикладных алгоритмов. Язык SQL продолжает оставаться прекрасным языком для управления данными, однако хранимые процедуры, являющиеся расширениями языка SQL и предназначенные для программирования и хранения внутри сервера прикладного кода, имеют очевидные слабые места.
Хранимые процедуры на SQL имеют очень ограниченный набор средств разработки и отладки, их невозможно вынести из сервера СУБД, а кроме того, в них отсутствует множество стандартных возможностей современных языков программирования, например использование внешних библиотек, механизмов инкапсуляции, наследования и других объектно-ориентированных особенностей.
Язык Java является естественным решением для программирования прикладного кода внутри сервера СУБД. Язык SQL продолжает использоваться для доступа к данным и манипуляций над ними.
Инсталляция классов в сервер
Произвольная программа на Java состоит из набора классов. Для их использования в Adaptive Server будет необходимо провести инсталляцию Java-классов в СУБД. Классы должны быть откомпилированы в байт-код (и, тем самым, готовы для исполнения в виртуальной Java-машине) вне сервера. После инсталляции они могут исполняться (и могут быть отлажены) внутри сервера СУБД.
Доступ к языку SQL из Java с помощью интерфейса JDBC
Для обеспечения работы прикладного Java-кода в базе данных, необходимо обеспечить интерфейс доступа из Java к языку SQL. Совершенно аналогично тому, как операторы SQL доступны для вызова из обычных хранимых процедур, они должны быть доступны для вызова из методов, описанных на языке Java.
На клиентской стороне, для включения языка SQL в Java-методы используется интерфейс JDBC. JDBC - это прикладной программный интерфейс, введенный в набор Java SDK версии 1.1.0, и предназначенный для включения операторов SQL в методы на Java.
Для уменьшения различий между программированием клиентских и серверных приложений, необходимо обеспечить JDBC-доступ к SQL-операторам из методов на Java, изнутри СУБД. Именно поэтому внутренний интерфейс JDBC для Adaptive Server является ключевой особенностью Java-инициативы компании Sybase.
Использование методов, упрощающих разработку под JDBC
Также как ODBC, JDBC представляет собой низкоуровневый прикладной интерфейс для доступа к СУБД. Аналогично тому, как во многих средствах быстрой разработки приложений существуют собственные высокоуровневые интерфейсы, построенные на основе ODBC, существует необходимость в интерфейсах на основе JDBC, которые позволят разработчикам быть более эффективными.
После того, как откомпилированные Java-классы будут инсталлированы в Adaptive Server, любые высокоуровневые инструменты и методы, генерирующие Java и JDBC-код, поддерживаются автоматически.
В их числе:
Перед компиляцией, JSQL-код преобразуется препроцессором в вызовы SQL. Пользователи Adaptive Server смогут, при желании, использовать JSQL и встраивать обработанный препроцессором код в сервер СУБД.
Одной из причин появления адаптивной компонентной архитектуры Sybase является четкое понимание важности компонентной разработки прикладных систем, которое позволяет ускорить создание надежных информационных систем с помощью повторного использования уже отлаженного кода.
Возможность использования компонентов JavaBeans на любых уровнях распределенной информационной системы, включая СУБД, позволит воспользоваться преимуществами языка Java при разработке корпоративных прикладных баз данных. Adaptive Server будет поддерживать исполнение компонентов кода на основе стандартов JavaBeans и Enterprise JavaBeans.
Повторное использование: основная причина поддержки Java
В связи с использованием виртуальной машины для исполнения методов на Java и встроенной поддержке интерфейса JDBC, один и тот же объект на языке Java (созданный непосредственно на JDBC, либо с помощью какого-либо RAD-средства, включая PowerJ) может быть использован как внутри, так и вне СУБД.
В компании Sybase существует четкое убеждение, что для получения максимальных выгод от использования Java, критически важным является отсутствие особых требований для Java-классов, предназначенных для встраивания в СУБД. В отличии от некоторых других подходов, реализация Sybase целиком основывается на этой важнейшей особенности.
Использование Java для описания объектных типов данных
В дополнении к созданию прикладного кода в СУБД, использование языка Java позволяет найти решение к другим ограничениям современных реляционных СУБД. В частности, использование этого языка предоставляет средства для расширения набора имеющихся типов данных.
Будучи установленным в Adaptive Server, Java-класс может быть использован в качестве типа данных для столбца таблицы. Каждое поле такой записи становиться экземпляром соответствующего Java-класса.
В качестве примера возьмем простой класс на языке Java, хранящий адреса. Вы можете создать и инсталлировать в Adaptive Server класс Address, содержащий информацию об улице, городе и почтовом индексе. После этого вы можете создать столбец с типом данных Address и вставить новый адрес. Доступ к различным полям класса Address в запросах может производиться раздельно.
Использование даже такого простого класса, каким является класс Address дает ряд преимуществ пользователям базы данных:
Возможность хранения объектов Java в реляционной СУБД является важной особенностью для корпоративных приложений. В частности, ожидается упрощение процесса внедрения и повышение количества повторно используемого кода.
Доступ к Java-объектам из языка SQL
Хотя интерфейс JDBC является стандартом индустрии для доступа к SQL из языка Java, в настоящее время не существует обратного стандарта, описывающего доступ к Java-объектам из SQL. Компания Sybase разработала такой интерфейс, и работает над его стандартизацией.
Основным принципом разработчиков этого интерфейса являлось избежание неочевидных языковых конструкций: с тем, что бы Java-объекты и внутри операторов SQL работали так, как это ожидается.
Язык Java и объектно-ориентированные СУБД
Термин "объектно-реляционная СУБД" предназначен для обозначения ряда технологий, предназначенных для пользователей, которым недостаточно стандартных типов данных, имеющихся в реляционных СУБД.
Одной характерной потребностью таких пользователей является возможность создания собственных базовых типов данных, которые могут быть специфичны для конкретной организации. В Sybase для этого используются Java-классы.
Кроме того, существует потребность в относительно небольшом количестве специализированных типов данных, таких как текст, геоинформационные данные, временные ряды и мультимедийные данные. Эти специализированные типы данных имеют специфические требования к индексации и работе с ними. Sybase поддерживает подобные типы данных через слой интеграции компонентов обработки данных, который встроен в Adaptive Server.
C помощью поддержки Java и встроенного слоя интеграции компонентов, Sybase создает объектно-реляционную СУБД, которая может быть оптимизирована для различных задач обработки данных.
Возможные проблемы при использовании Java
Безопасность и производительность являются наиболее частыми предметами для размышления для администраторов баз данных и отделов информационных технологий. Обсуждение реализации требований по безопасности и производительности в Java также являются предметом постоянной дискуссии в Java-сообществе.
Вопросы безопасности
Вопросы безопасности и целостности являются важнейшими для организаций, которые хранят свои данные в реляционных СУБД. Как поставщик технологий для корпоративных информационных систем, компания Sybase осознает эти требования и именно поэтому применяется архитектура Java. Например:
Вопросы производительности
Несмотря на то, что производительность Java-приложений является популярной темой для обсуждения, компания Sybase разделяет мнение многих специалистов, считающих, что подобные опасения исчезнут в течении следующего года. Аналитик Stan Doelberg из компании Forrester Research, обсуждавший недавно данную проблему, полагает, что "в течении шести месяцев проблема производительности будет снята"#.
Различные разработчики компиляторов, включая соответствующее подразделение в Powersoft, продолжают работать над улучшениями языка. Пользователи Adaptive Server смогут воспользоваться этими разработками, после того, когда они установят скомпилированные Java-классы в сервер СУБД.
Дополнительно, администратор СУБД сможет настраивать параметры хранения объектов в классе.
Использование Java в СУБД и клиентские приложения
Компания Sybase стремиться к созданию решений, которые бы позволяли сохранять сделанные существующими пользователями инвестиции в современную технологию. Уже существующие прикладные системы не должны изменяться для того, что воспользоваться новыми особенностями Adaptive Server.
Java-особенности СУБД Adaptive Server доступны существующим прикладным системам, включая те, которые не используют Java, а применяют интерфейс ODBC или библиотеку Open Client. Клиентские приложения, использующие Java, могут использовать дополнительные возможности.
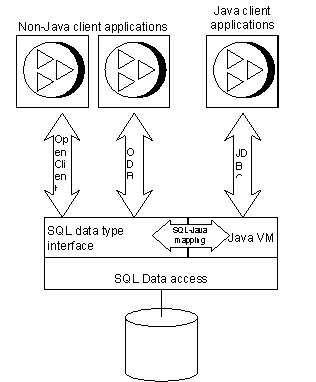
Поддержка всех клиентских приложений
Поддержка Java-архитектуры СУБД Adaptive Server для клиентских приложений, которые не используют Java, основывается на внутреннем отображении (internal mapping) языков Java и SQL. Клиентское приложение общается с сервером, используя стандартный интерфейс, например Sybase Open Client или ODBC. Доступ к полям, основанных на Java-объектах, производится с помощью стандартных операторов SQL. При этом методы Java вызываются и исполняются совершенно так же, как и обычные хранимые процедуры. На клиентском приложении в этом случае доступны только стандартные типы данных.
Поддержка клиентских приложений на Java
Клиентское приложение на Java сможет соединяться с Adaptive Server с помощью интерфейса JDBC. В дополнении к возможностям, которые доступны не Java-приложениям, клиентские Java-приложения смогут обмениваться объектами с Adaptive Server.
Когда Java-объект запрашивается с сервера, он посылается к клиентскому приложению и исполняется на клиентской виртуальной Java-машине.
Как уже подчеркивалось ранее, реализация Java архитектуры в Adaptive Server такова, что, в отличии от других технологий, классы не требуют какой-либо особой подготовки для использования в СУБД. Класс может быть использован в клиентском приложении, промежуточном сервере приложений, или же перенесен в СУБД без всяких модификаций, что упрощает создание распределенных приложений.
Например, если метод city из класса Address вычисляет название города из значения поля Postal Code, то этот может быть вызван как с клиента, так и из сервера.
Заключение
Деятельность компании Sybase направлена на решение проблем организаций, которые создают и эксплуатируют информационные системы. Стратегия использования Java-технологии в Adaptive Server позволяет убрать искусственные барьеры, усложняющие и без того непростые задачи автоматизации.
Java представляет собой новый язык программирования для разработки прикладных программ, а дополнительные технологии JavaBeans и Enterprise JavaBeans являются важными объектными моделями для создания приложений на Java. В то же время, реляционные СУБД являются наиболее широко используемым типом СУБД для решения задач бизнеса. Возможность хранить и запускать Java-объекты в реляционных СУБД открывают новые возможности для корпоративных разработчиков, а также позволяет использовать достоинства Java при разработки корпоративных прикладных информационных систем.
Sybase
Алексей Тимонин
Тел.: (095) 956-2016 Факс (095) 956-2041
Назад | Содержание | Вперед