В фазе анализа VantageTeam Builder предоставляет средства разработки диаграмм Потоков данных,
используемых как для описания взаимодействия системы с внешним миром (контекстная диаграмма),
так и для определения структуры процесса обработки информации (диаграммы потоков данных
более низких уровней). При желании возможно формализованное задание требований к
разрабатываемой системе в виде Списка событий. В этом случае обеспечивается контроль
соответствия контекстной диаграммы и Списка событий. Кроме того обеспечивается контроль
правильности декомпозиции диаграмм при переходе с уровня на уровень.
Для разработки модели данных предлагается весьма широкий спектр средств, включающий в себя
диаграммы Структуры данных, диаграммы Отношений сущностей и текстовое описание в форме
Бэкуса-Науэра. Различные типы диаграмм сравниваются между собой на непротиворечивость.
С использованием оригинальных диаграмм Архитектуры системы вы можете разработать архитектуру
вычислительного комплекса и уточнить аппаратное оснащение рабочих мест системы. Определяется
распределение задач между вычислительными средствами, а также потоки данных между
вычислительными средствами, задачами (отдельными исполняемыми модулями) и процессами
обработки информации в составе одной задачи. Создаются спецификации (формализованные
описания) процессов обработки информации нижнего уровня. При необходимости возможно введение
управляющих потоков между процессами обработки информации и разработка их структуры с
помощью специальных диаграмм. Для описания воздействий управляющих потоков возможно
использование диаграмм Изменения состояний.
Для описания необходимой структуры базы данных используются диаграммы Отношений сущностей в
нотации Чена [4]. Они позволяют указывать различные типы реляционных
отношений между таблицами (общее, тотальное, слабое, рекурсивное), связи различной мощности (1-1,
1-N, N-N), а также различные суб- и супертипы, ассоциированные сущности и связи с атрибутами.
Диаграммы Структуры данных и аналогичные им по нотации диаграммы Структуры управляющих
потоков могут использоваться для определения структуры и типов программных переменных.
В фазе Архитектуры начинается определение принципов построения интерфейса системы с
использованием диаграмм Последовательности экранных форм. Они позволяют указывать как
условия переходов между экранными формами, так и выполняемые при этом действия.
Фаза дизайна завершается, по словам разработчиков CASE'а, за один шаг до программы. Здесь
осуществляется окончательная отработка модели данных, функциональной модели и проектирование
интерфейса системы с помощью уже упоминавшихся диаграмм, а также ряда специальных типов
диаграмм, позволяющих однозначно сформулировать требования к интерфейсу и программе.
Разработка структуры базы данных предполагает полное описание всех атрибутов сущностей (полей
таблиц). Для этого используется механизм логических типов данных и логических ограничений,
практически полностью поддерживающий понятие домена. Возможно задание внешних (используемых
при работе с заказчиком и в документации) и внутренних (программных) имен таблиц, полей и
программных переменных. Определяются необходимые политики поддержания целостности базы по
ссылкам при основных действиях (INSERT, UPDATE, DELETE) с различными таблицами.
В основу разработки приложения положены интегрированные диаграммы Последовательности
экранных форм. В фазе дизайнера в этих диаграммах для каждой формы указывается имя диаграммы
Содержания экранной формы и имя Структурной схемы программного модуля, реализующего
соответствующий процесс обработки информации.
Диаграмма Содержания экранных форм позволяет указать таблицы и их поля, представленные в
форме, способ их представления (список - полноэкранная форма), а также основные функциональные
возможности (доступность таблиц на запись или только для чтения информации). При этом неявно
определяется разделение таблиц на группы, включающие в себя одну или несколько основных
(базовые) таблиц и связанные с ними отношением N-1 словари. На диаграмме можно указать
необходимость открытия просмотрового окна для организация поиска значений в соответствующем
словаре.
Структурные схемы программ - универсальное средство описания функциональных возможностей
приложения. Они позволяют описать любую программу с произвольной точностью (до функции,
до группы операторов, до отдельного оператора, до отдельных составляющих оператора типа
структуры AFTER FIELD в операторе INPUT). Основными элементами структурных схем являются
заголовок или вызов функции, хэт-модуль ("модуль со шляпой", что соответствует используемому для
него обозначению), позволяющий записать произвольные конструкции на языке программирования и
указания относительно их размещения в программном файле (например, из любого хет модуля
можно добавить определение еще одной переменной в секцию описания глобальных, модульных
или локальных переменных, добавить в файл описание еще одной функции и т. п.), операторы выбора
(MENU, IF, IF ... ELSE, CASE), операторы повтора (WHILE, FOR) и библиотечные
(предопределенные или стандартные модули), представляющие собой, как будет показано ниже,
весьма мощный инструмент быстрой разработки приложений.
3. VantageTeam Builder для программиста.
Рассмотрим основные действия программиста, осуществляющего разработку проекта с
использованием VantageTeam Builder.
SQL-скрипт для создания базы со всеми необходимыми операторами CREATE TABLE (с указанием
необходимых ограничений), ADD FOREIGN KEY и CREATE PROCEDURE генерится
автоматически. При этом для каждой таблицы создается описание трех хранимых процедур,
обеспечивающих выполнение функций INSERT, UPDATE и DELETE. Использование процедур в
приложении позволяет обеспечить выполнение требуемых политик поддержания целостности базы
по ссылкам.
Скрипт выполняется с помощью DBACCESS.
Экранные формы генерятся автоматически в соответствии с диаграммами Содержания экранных
форм при переносе проекта в фазу Программирования. Их ручная доработка в части более
рационального или эстетичного размещения полей по экрану может осуществляться в любом
текстовом редакторе.
Включает следующие стадии:
- реализация описаний процессов обработки информации, выполненных в предыдущих фазах разработки для отдельных структурных элементов и не представленных на диаграммах своей декомпозицией, в виде фрагментов программного кода. Этот код записывается в виде спецификаций для соответствующих элементов структурной схемы;
- автоматическая генерация текста программных файлов, включая сбор и размещение в файле спецификаций элементов структурной схемы, а также генерацию текстов по шаблонам для библиотечных модулей.
VantageTeam Builder предлагает программисту достаточно удобные инструменты для описания
приложения, как совокупности программных, объектных и библиотечных файлов, зависимостей
между файлами с исходными текстами программ и между другими входящими в приложение файлами.
На основе этого описания для приложения автоматически генерится makefile, управляющий
компиляцией и сборкой программы. По желанию может быть собран как файл с интерпретируемым,
так файл с исполняемым кодом программы.
4. Средства ускорения разработки приложений
Как видно из предыдущего описания, VantageTeam Builder позволяет вести разработку проектов
весьма высокой сложности. Графические редакторы и средства контроля существенно упрощают
анализ задачи и проектирование приложения, упрощая и ускоряя работу аналитиков и
проектировщиков. Программист же получает на первый взгляд не так уж много:
- удобный инструмент создания базы данных с генерацией полезных хранимых процедур;
- несколько более удобный, чем опция Forms в стандартной среде разработки Informix-4GL, инструмент генерации экранных форм, который сразу формирует экранные массивы и нужные пользователю названия полей, в том числе, на русском языке;
- возможность придерживаться классического структурного подхода, поскольку программирование теперь выглядит как "вписывание" необходимых операторов в соответствующие элементы структурной схемы программы.
В VantageTeam Builder поддерживаются библиотечные модули для реализации и вызова базовых SQL-
функций доступа к таблицам базы данных. Разработчик может пользоваться этим инструментом для
создания собственных, личных (или проектных) библиотек модулей. Каждый такой модуль является
атомарным (детально не раскрываемым) элементом структурной схемы программы. Они
предназначены для выполнения двух задач.
Первая, это создание библиотеки стандартных (непараметризуемых) фрагментов текста, например:
INPUT BY NAME p_record.*
--начало библиотечного модуля
ON KEY (ESC)
LET INT_FLAG = true
EXIT INPUT
--конец библиотечного модуля
Вторая - это создание библиотеки шаблонов, используемых для генерации параметризуемых
фрагментов текста, например (имя таблицы и имена полей определяются в данном примере
параметрически):
--начало библиотечного модуля
INPUT BY NAME p_{имя таблицы}.*
ON KEY (ESC)
LET inf_flag = true
EXIT INPUT
ON KEY(CONTROL-U)
--для всех импортированных полей
IF INFIELD({имя поля}) THEN
CALL find_{имя таблицы}(p_{имя таблицы}.{имя поля})
RETURNING p_{имя таблицы}.*
END IF
END INPUT
--конец библиотечного модуля
Соответственно дизайнер может использовать один и тот же библиотечный модуль на различных
схемах, а программист один раз пишет необходимый код или шаблон. Шаблоны представляют собой
текст программы, содержащий вызовы специальных функций, написанных на языке Tool Command
Language (TCL), и обеспечивающих чтение информации из формируемых с помощью VantageTeam
Builder моделей (диаграмм) и запись сформированного текста в соответствующие разделы
генеримого файла с кодом программы или SQL-скрипта. Например, шаблон для приведенного
выше примера выглядит следующим образом:
--начало шаблона
INPUT BY NAME p_~${current_table}.*
ON KEY (ESC)
LET inf_flag = true
EXIT INPUT
ON KEY(CONTROL-U)
~[ foreach col [gen_col_list $current_table "FKEY"] {
set master_table [get_master $col]
set col_name [get_uniq_name $col]
expand_text $current_section {
IF INFIELD(~$col_name) THEN
CALL find_~${master_table}()
returning p_~$current_table.~$col_name
END IF
END INPUT
--конец шаблона
Здесь:
- current_table - переменная, в которой хранится имя текущей таблицы;
- foreach - команда цикла по всем импортированным из других таблиц полям текущей таблицы;
- get_master и get_uniq_name - функции, обеспечивающие чтение имени связанной таблицы и импортированного поля;
- expand_text $current_section - команда, обеспечивающая запись сгенеренного текста в программный файл.
Таким образом, если ваша новая программа повторяет структуру одной из ваших старых программ, а для всех фрагментов кода, содержащих имена полей и таблиц, вы разработали соответствующие шаблоны, вы можете просто указать на диаграмме Последовательности экранных форм для всех форм, в которых необходимо выполнить однотипные действия, имя одной и той же структурной схемы программы. В результате вы получите автоматически сгенеренную программу "по старому образцу" для нового набора полей и таблиц. Причем операция подстановки в старую программу новых имен полей и таблиц будет выполнена весьма быстро и заведомо корректно без досадных пропусков и опечаток.
В стандартную поставку VantageTeam Builder входит набор библиотечных модулей для генерации
меню по диаграмме последовательности экранных форм и для выполнения стандартных действий
(insert, update, delete) для базовых таблицы определенной экранной формы. Поэтому вы можете
ограничиться следующей последовательностью действий для получения полностью функционального
приложения (обеспечивающего выполнение всех необходимых действий с таблицами базы данных), с
единообразным интерфейсом.
Шаг1. Разработка структуры базы данных с использованием диаграмм отношений
сущностей.
Шаг2. Разработка интерфейса приложения с использованием диаграмм последовательности
экранных форм. В последовательности экранных форм используются формы двух видов - формы-
меню и формы для работы с одной или несколькими таблицами базы данных. Формы-меню
обеспечивают выбор таблицы (группы таблиц), с которой вы собираетесь работать.
Шаг3. Для форм, предназначенных для работы с одной таблицей, ее имя указывается в
атрибутах формы, а для форм, предназначенных для работы с полями нескольких таблиц, создаются
диаграммы содержания экранных форм.
Шаг4. К формам-меню привязывается структурная схема, основным элементом которой
является библиотечный модуль "MENU". К формам, предназначенным для работы с таблицами
привязывается стандартная структурная схема, обеспечивающая выполнение стандартных действий
(insert, update, delete, find).
Все вышеперечисленные действия выполняются в фазе дизайна. В результате при переходе в фазу
программирования вы получаете не только готовый SQL-скрипт и экранные формы, но и полностью
готовое автоматически сгенеренное приложение. Скорость разработки простых проектов при этом
оказывается вполне сопоставимой с такими популярными средствами разработки приложений, как
PowerBuilder и Delphi.
Описанная выше технология позволяет использовать VantageTeam Builder как средство ускоренной
разработки приложений с однотипным интерфейсом и функциональными возможностями для
различных таблиц. Однако, она не свободна от ряда недостатков, существенно снижающих ее
достоинства. Одним из них является выбранный для разработки шаблонов эталон интерфейса и
программного кода. Он:
- не поддерживает альтернативных ключей, что весьма затрудняет использование сериальных полей;
- не обеспечивает возможности проведения групповых операций с записями;
- увы, в части интерфейса довольно старомоден и не нравится пользователям, уже привыкшим к графике.
С учетом соотношения цен вряд ли целесообразно использовать VantageTeam Builder при разработке относительно простых приложений. В более сложных же проектах неизбежно возникает проблема доработки автоматически сгенеренных кодов программ с целью выполнения специфических требований заказчика касательно работы с конкретными таблицами. Причем чем крупнее проект, тем больше таких специфических таблиц и тем лучше эти изменения должны быть задокументированы. При выбранной же структуре шаблонов внесение даже таких мелких изменений, как использование дополнительных опций оператора INPUT (например, BEFORE INPUT или BEFORE FIELD), означает либо незадокументированное и, следовательно, не воспроизводимое при необходимости повторной генерации текста ручное внесение исправлений в автоматически сгенеренный текст, либо отказ от использования шаблонов и переход на практически ручное (хотя и структурное) программирование.
5. Генератор GRINDERY On-Step 4GL
Перечисленные выше недостатки стандартных шаблонов VantageTeam Builder заставили нас
задуматься о разработке собственных шаблонов. При этом необходимо отметить, что произошло это
еще при использовании CASE'а версии 3.1. В отличии от версии 3.2. он не позволял использования
одной и той же структурной схемы для различных экранных форм (в библиотечных модулях было
необходимо явно указывать, для какой таблицы необходимо сгенерить код) и не поддерживал
диаграмм Содержания экранных форм. Поэтому для реализации идеи автоматической генерации
значительной части кода приложения с достаточно большими функциональными возможностями
было необходимо строго формализовать не только принципы формирования программного кода, но и
принципы построения экранной формы.
Рассмотрение в данном разделе инструмента кодогенерации будет проводится на примере алфавитно-
цифровой среды разработки приложений INFORMIX-4GL, что не является ограничением общности
подхода, как это будет видно из дальнейшего, но удобно для нас с методологической точки
зрения.
Проведенный анализ нескольких разнохарактерных приложений, разработанных ранее как фирмой
DataX/FLORIN, так и некоторыми другими (среди них можно упомянуть научную информационную
систему FLORIN, прикладную медицинскую систему, бухгалтерские системы) привел нас к следующей
модели работы с отдельной таблицей и ее словарями, позволяющей в определенной мере преодолеть
ограничения алфавитно-цифрового интерфейса.
Как легко видеть, эталонный интерфейс для работы с произвольной таблицей базы данных включает
три экранные формы:
- форма ввода и модификации информации - add_form (она же используется для просмотра записей при удалении - delete_form);
- форма формирования запроса на поиск - find_form;
- форма списка с двумя подрежимами :
а
- список с отметками, в котором можно отметить одну или более записей для проведения с ними определенной операцией - list_form; а
- список с выбором единственной - choose_form (для выбора записей из словарей при экспорте ссылок или значений в вышестоящую таблицу).
При формировании полноэкранной формы для работы с таблицей и ее словарями поля базовой таблицы разбиваются на видимые и невидимые (но поддерживаемые программой). К последним, как правило, относятся уже упоминавшееся сериальное поле, импортированные из словарей (master- tables) их сериальные поля, а также (в нашей разработке, реализуемой с помощью генератора) поля с логнеймом внесшего последнее изменение в данную запись и временем этого изменения. Все словари единообразно представляются на экране одним "вычисляемым" полем, которое мы традиционно используем для "строчного" представления записи, получаемого конкатенацией наиболее важных для пользователя полей таблицы. Импортированные ключевые поля словарей используются в программе для определения связи между таблицами.
Одним из принципиальных моментов интерфейса является то, что строковое представление для таблицы единственно и используется как в полях для словарных значений, так и при формирование списков с отметками и списков для выбора.
Хотя это является явным "ограничением общности", принятое решение представляется нам весьма разумным, ибо приучает пользователя к единообразному представлению записи, где бы она не появилась.
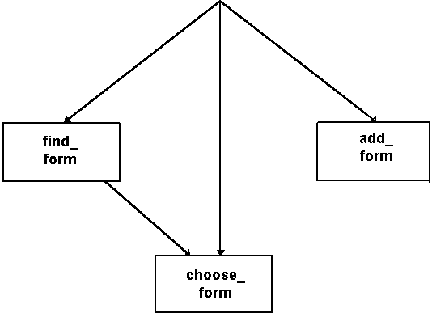
Рис.1. Диаграмма последовательности экранных форм при обращении к таблице как к словарю.
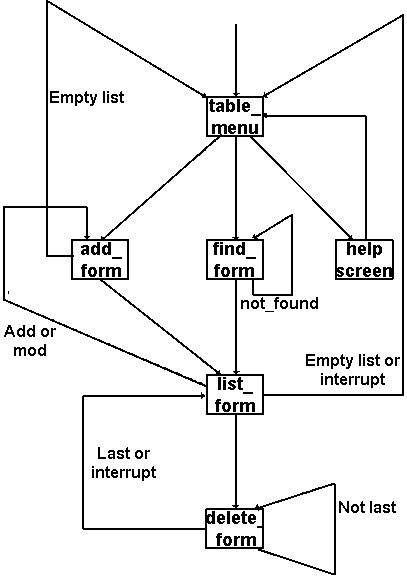
Рис.2. Основная диаграмма последовательности экранных форм для отдельной таблицей.
Одним из инструментов VantageTeam Builder, поддерживающих генерацию по шаблону, являются
задаваемые пользователем атрибуты для любых элементов любых типов диаграмм. Детальный анализ
эталонного интерфейса показал, что его реализация требует задания для каждой таблицы и ее
полей некоторых дополнительных атрибутов, среди которых основными являются признак видимого
поля, признак вхождения поля в альтернативный ключ, признак вхождения поля в строковое
представление, тип вычисляемого поля для представления словарной таблицы. Перечисленные выше
атрибуты наиболее естественным образом могут быть введены на ER-диаграммах, поскольку при
принятой нами логике построения приложения, их значения единственны для всех форм, имеющих
отношение к данной таблице.
Отсутствие в CASE'е версии 3.1 инструментов генерации сложных экранных форм привело к
необходимости построения собственного генератора экранных форм, генерящего для каждой
таблицы формы для ввода/модификации информации и для формирования запросов, который также
вошел в состав GRINDERY One-Step 4GL.
С точки зрения скорости получения работающего приложения, чем крупнее шаблон, тем лучше.
Соответственно, мы ограничились одним шаблоном на весь набор функций, обеспечивающих работу
с таблицей (в отличие от VantageTeam Builder, мы генерим не одну функцию, а несколько,
основными из которых являются функция для ввода/модификации, функция для удаления
отмеченных в списке записей, функция просмотра записи, соответствующей "словарному" полю или
строке в списке, функция ввода запроса и формирования списка найденных записей и функция
формирования строкового представления). Однако, пойдя по такому пути мы не могли не столкнуться
с проблемой доработки прототипа. Вносить в него изменения вручную легче, чем в текст,
генерящийся по стандартным шаблонам, поскольку он разбит на отдельные функции и уже за счет
этого лучше структурирован. Сложность же здесь, как и при использовании стандартных шаблонов,
возникает прежде всего потому, что при внесении изменений непосредственно в текст модуля с одной
стороны ухудшается степень документированности проекта, а с другой теряется возможность
перегенерации кода программы при внесении каких-либо изменений в структуру таблиц или
переназначении дополнительных атрибутов. В настоящее время для решения этой проблемы
изменения, которые вносятся в текст программного модуля, записываются в специальные файлы (по
одному на каждый модуль) со специальными метками, указывающими куда именно внесено
изменение. Таким образом достигается и определенная документированность внесенных уникальных
изменений (хотя они и не отражаются на каких-либо диаграммах, их значительно легче найти в таком
файле, чем в полном тексте программы,) и их повторное использование при перегенерации
программы.
Написанный нами кодогенератор прошел серьезную практическую проверку как основной инструмент
написания кода при разработке системы автоматизации коммерческой и производственной
деятельности нашей фирмы. С его помощью было сгенерено не менее 80% общего объема приложения
(около 2 Мб исходных текстов программ) и почти все экранные формы. В целом он, по нашим
оценкам, сократил в несколько раз время написания кода по сравнению с проектами, выполнявшимися
вручную. Существенно упростилась отладка и тестирование приложения, поскольку из автоматически
сгенеренного кода для работы с примерно полусотней таблиц достаточно проверить один-два
стандартных варианта. Тщательного тестирования требуют лишь те 20% кода, которые написаны
полностью или частично вручную.
Конечно, разнообразие потребностей пользователей, а соответственно и разработчиков не позволяет
считать принятые решения лучшими или единственно правильными для всех. Несомненно следующая
версия нашего кодогенератора будет более гибкой как за счет разбиения шаблонов на более мелкие
фрагменты (в которые легче внести необходимые изменения), так и за счет использования диаграмм
содержания экранных форм (прежде всего для задания необходимой функциональности конкретного
модуля).
Другое направление, в котором мы надеемся усовершенствовать кодогенерацию, это повышение
степени документированности вносимых изменений. И здесь, как нам кажется, нам удалось найти
интересное решение, основанное на возможности CASE'а версии 3.2. использовать одну структурную
схему для генерации программных модулей, предназначенных для работы с различными
таблицами.
6. VantageTeam Builder и GRINDERY как средства разработки приложений для NewEra и SuperNOVA
Получив такие результаты в части генерации 4GL приложений мы задумались над тем, нельзя ли
приспособить кодогенератор к разработке приложений с использованием других средств разработки,
прежде всего NewEra и SuperNOVA. Дело в том, что эти средства являются объектно-
ориентированными и поддерживающими графический интерфейс. Теоретически разработка
приложений для средств такого класса (также, как и приложений на С++) должна вестись с помощью
CASE-средств, поддерживающие объектно-ориентированный подход, например, с помощью
VantageTeam OO Builder той же фирмы CADRE. Однако такие средства разработки пока не
пользуются в России заметной популярностью, что связано, видимо, с относительной новизной
подхода и меньшей наглядностью проектов, выполненных с помощью какой-либо из объектно-
ориентированных методологий. Фактически многие разработчики предпочли бы выполнять анализ и
проектирование на основе структурного подхода, а разработку интерфейса и генерацию приложения
вести с помощью объектно-ориентированных инструментов. И, как показал наш анализ, VantageTeam
Builder вполне может справиться с этой задачей. Для этого его достаточно оснастить соответствующей
версией нашего генератора GRINDERY NewEra/Yourdon или GRINDERY SuperNOVA /Yourdon
Описанный выше подход, использовавшийся нами при разработке генератора 4GL приложений,
оказался достаточно близок к объектному. Фактически, для каждой таблицы создается объект,
состоящий из ее (видимых и невидимых) полей, импортированных полей и строковых представлений
словарей. А выбранный эталон программной реализации по сути близок к стандартному набору
методов для работы с построенным объектом. Это позволяло надеяться на относительную простоту
переноса основных решений, используемых для процедурного языка Informix-4GL, на объектные языки
NewEra и SuperNOVA.
Тем не менее, при построении генераторов для NewEra и SuperNOVA нам пришлось решать весьма
сложный принципиальный вопрос: как осуществить переход между богатыми возможностями
графического интерфейса и значительно более ограниченными возможностями алфавитно-цифрового?
В отличие от многих универсальных (позволяющих для одного приложения создавать и такой, и
другой интерфейсы) средств разработки (к которым, кстати, относится и SuperNOVA) мы пошли не по
пути копирования экрана, а по пути реализации аналогичного по функциональным возможностям
набора методов. Выбор такого подхода во многом перенес тяжесть разработки на создание
необходимой библиотеки классов, оставив задачей кодогенератора создание файлов прототипов
экранных форм (WIF-файлы для NewEra и LGC-файлы для SuperNOVA). В результате кодогенератор,
создающий необходимые WIF-файлы на основе все того же проекта, разработанного с помощью
VantageTeam Builder, был написан еще быстрее, чем генератор для разработки 4GL приложений.
Несколько выводов
Если попытаться сделать выводы из всего описанного выше, то необходимо прежде всего отметить
следующее:
- Входящий в состав VantageTeam Builder кодогенератор является весьма мощным и гибким средством, позволяющим свести значительную долю рутинной работы программиста по написанию программ "по образцу" к однократному написанию этих самых образцов. Причем в отличие от многих билдеров вы можете непосредственно видеть сгенеренный текст и вносить изменения как в него, так и в те шаблоны, по которым он генерится.
- VantageTeam Builder в комплекте с генератором GRINDERY позволяет использовать один и тот же проект для генерации приложений на таких различных языках, как Informix-4GL, NewEra и SuperNOVA. Это, в частности, позволяет упростить переход от Informix-4GL к NewEra и само освоение объектных подходов к разработке приложений.
Литература
- А.Закис, М.Макаров, Н.Приезжий. Применение интегрированной CASE-технологии фирмы Wesmount для разработки информационных систем. DBMS/RE, #2, 1995.
- А.М.Вендров. Один из подходов к выбору средств проектирования баз данных и приложений. СУБД, #3, 1995.
- E. Yourdon & L.L. Constantine. Structure Design, Fundamentals of a Discipline of Computer Program and System Design. Yourdon Press, Englewood Cliffs, 1979.
- P.P. Chen (editor). Entity Relationship Approach to System Analysis and Design. North Holland Publishing Company, 1980.